Event Loop
關於 Event Loop 也寫了兩篇, 針對瀏覽器和 Node.js 版本
透過以下兩篇可以更加清楚了解兩者之間的差異
Event Loop 運行機制解析 - 瀏覽器篇 -> 此為個人部落格連結
Event Loop 運行機制解析 - Node.js 篇 (本篇)
前言
去年說好要寫的 Event Loop - Node.js 篇終於完成了
話不多說, 直接來看一個範例, 這個範例在 瀏覽器 和 Node.js 上執行上會不會一樣?
setTimeout(()=>{
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
setTimeout(()=>{
console.log('timer2')
Promise.resolve().then(function() {
console.log('promise2')
})
}, 0)
.
.
.
.
.
.
.
.
.
答案是: 只有在 node v10 以前不一樣 (包含 v10)
瀏覽器會印出
// timer1
// promise1
// timer2
// promise2
Node.js v10 以前會印出, 但 v11 以後就會跟 browser 一樣
// timer1
// timer2
// promise1
// promise2
有些人用 v8, v10 "有時候"也會執行出跟 v11 一樣的結果
這其實有關於 setTimeout 底層的機制和機器效能有關
這個會放在最後補充做說明, 但我們先完整了解 Event Loop 後
再來解析為何 "有時候" 執行結果會跟 v11 一樣
但為什麼以前會不一樣, 以後卻會一樣?
這其實牽涉到 Event Loop 實作的原理
我們就透過這個例子, 往下慢慢介紹 Event Loop in Node.js
現在蠻多文章還是停留在 v10 版本之前的 Event Loop
這邊就直接以 v10 以前, 以及 v11 以後去做介紹和區別
Node.js Event Loop
在整個 Event Loop 中, 最核心的就是執行各種 callback
而何謂『執行各種 callback』
以一個生活化例子想像, 煮水的時候, 你什麼時候知道要去把瓦斯關掉?
就是當水壺在叫的時候, 會觸發你去關瓦斯, 關瓦斯這件事就是你的 callback
雖然實際上在 Node.js 裡面, 真正去煮水的不會是 Event Loop 本人
有時會是其他人去幫你煮水, 而 Event Loop 就是一直去問那個『其他人』, 水到底煮好沒
而這邊用的水壺, 可能就是不會叫的那一種, 必須要有其他人盯著看才知道有沒有煮好
而這裡的『其他人』可能是 Kernel or Thread Pool
詳細後面會介紹到, 這裡先有個概念就好
所以在整個 Event Loop 中, 會不斷接受到各種事件完成的通知
Event Loop 就會去執行事情通知完成後, 接著要做的事
像是發網路請求, 等到對方網路完成後會告訴你有回應了, Event Loop 就會去執行相對應的 callback
但這裡發網路請求, 是透過『其他人』去幫忙處理的, 也就是 Kernel or Thread Pool
Event Loop 本身只負責執行 callback
Event Loop 如其名, 就是一個 Loop, 會一直去檢查有沒有各種 callback 可以呼叫
但在檢查整個 callback 的過程中, 又會被細分多種 phase
不過個人覺得用純文字解釋容易恍神, 就直接上了兩種版本的 Event Loop 的圖
建議是可以先看 v10 以前的 Event Loop 去了解脈絡, 再去看 v11 以後
在下面圖中, 我略過了 idle & preare 這一個 phase
這個 phase 拿掉是不影響解釋整體 Event Loop
Node.js 官網也是標注僅內部使用, 但詳細的內容可能會在之後針對 libuv 的介紹去提到
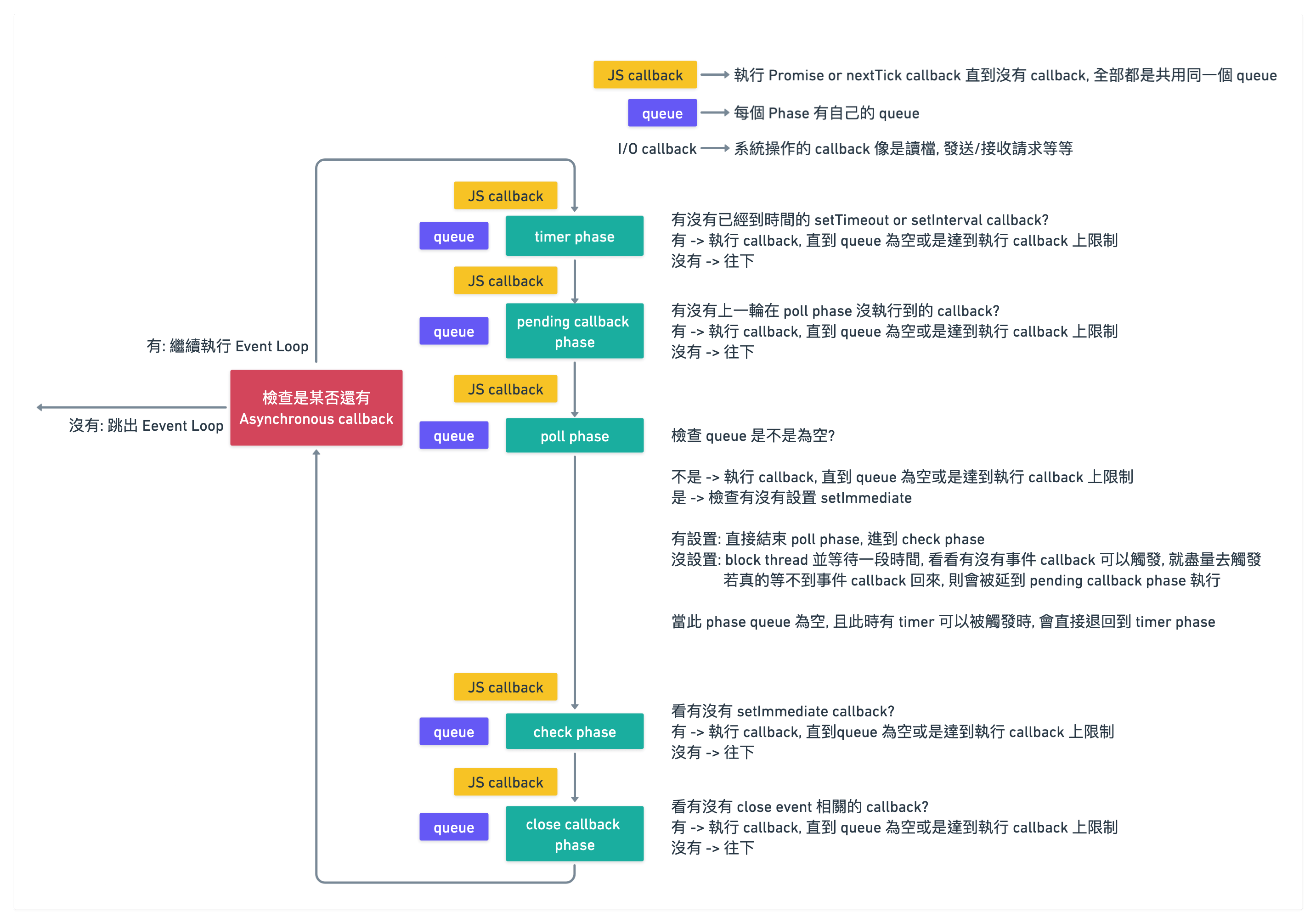
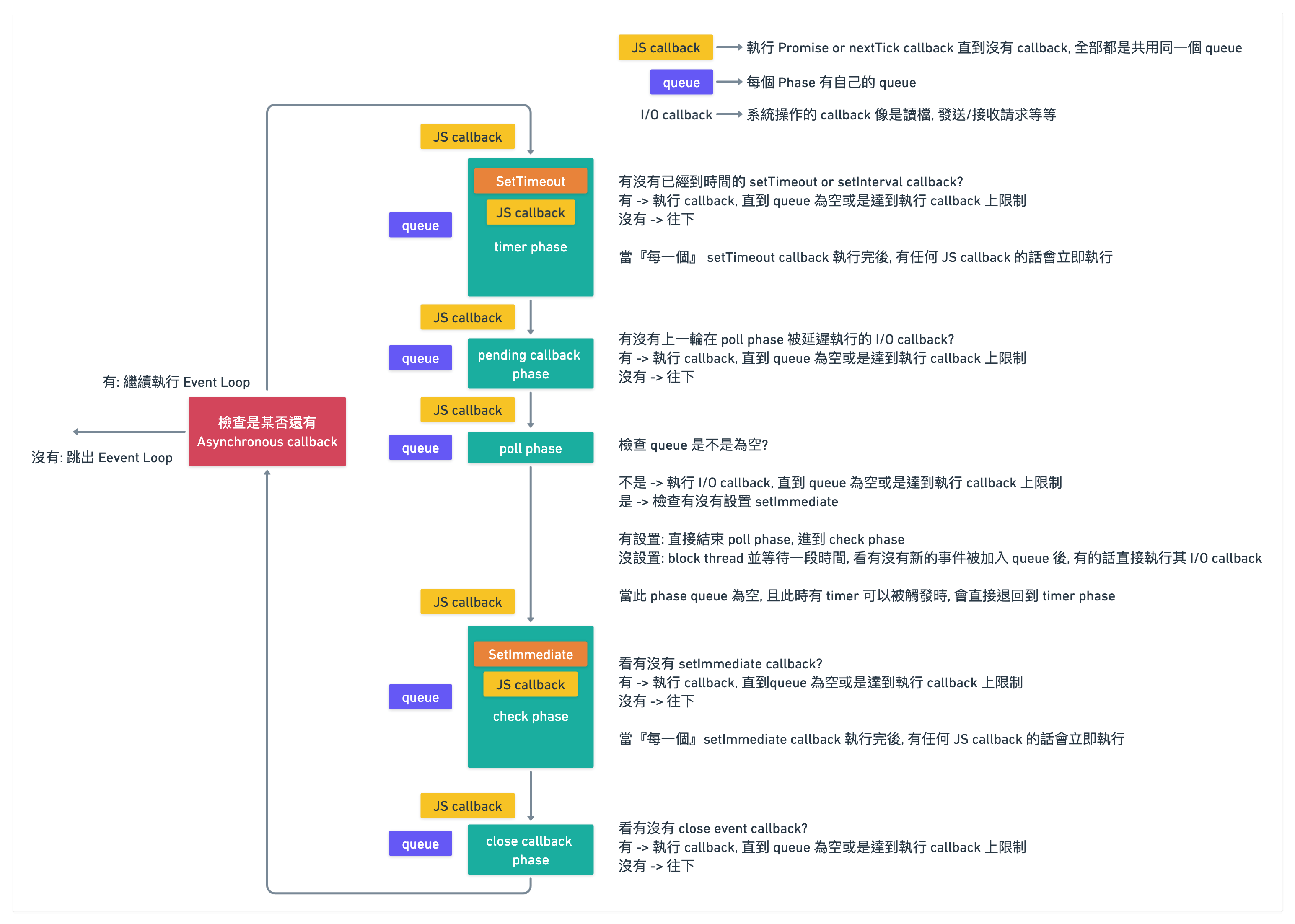
補充: 因為資料結構是 queue, 所以都是 FIFO 唷
兩者 Event Loop 最大差別在於
新版的在執行完『每一個』 setTimeout/setImmediate callback 後, 會執行 JS callback (promise or nextTick)
接著比較有爭議的是 pending callback phase 這兩個解釋
在有些比較久的文章上是叫做 I/O callback, 而目前在 Node.js 官網上 pending callback
這邊我就參照目前 Node.js 官網最新的名稱
Node.js 官網上是這樣說明的
在 Phase Overview 這樣寫
pending callbacks: executes I/O callbacks deferred to the next loop iteration.
在 Phase in Detail 這樣寫
This phase executes callbacks for some system operations such as types of TCP errors.
For example if a TCP socket receives ECONNREFUSED when attempting to connect,
some *nix systems want to wait to report the error.
This will be queued to execute in the pending callbacks phase.
libuv 的官網卻是這樣寫
All I/O callbacks are called right after polling for I/O, for the most part.
There are cases, however, in which calling such a callback is deferred for the next loop iteration.
If the previous iteration deferred any I/O callback it will be run at this point.
這樣結合一起看後, 基本上 pending callback phase 就是執行上一輪 poll phase 沒有成功觸發的 callback
只是 Node.js 官網比較詳細解釋, 像是 TCP error 也會被特意安排在這個 phase 去進行執行
執行範例解釋
接著我們按照這兩張圖個別的邏輯, 去解釋剛剛的那一段程式碼
setTimeout(()=>{
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
setTimeout(()=>{
console.log('timer2')
Promise.resolve().then(function() {
console.log('promise2')
})
}, 0)
v10 以前思考方式
在圖中的前段可以看到, 是先執行 JS callback 再執行 timer callback
但這裡主程式執行後, 並沒有 promise 可以執行, 只有看到 timer
此時就會先把 timer 塞到 timer phase 裡面的 queue 去
queue 裡面就會有 [timer1 callback, timer2 callback] 這樣資料存著
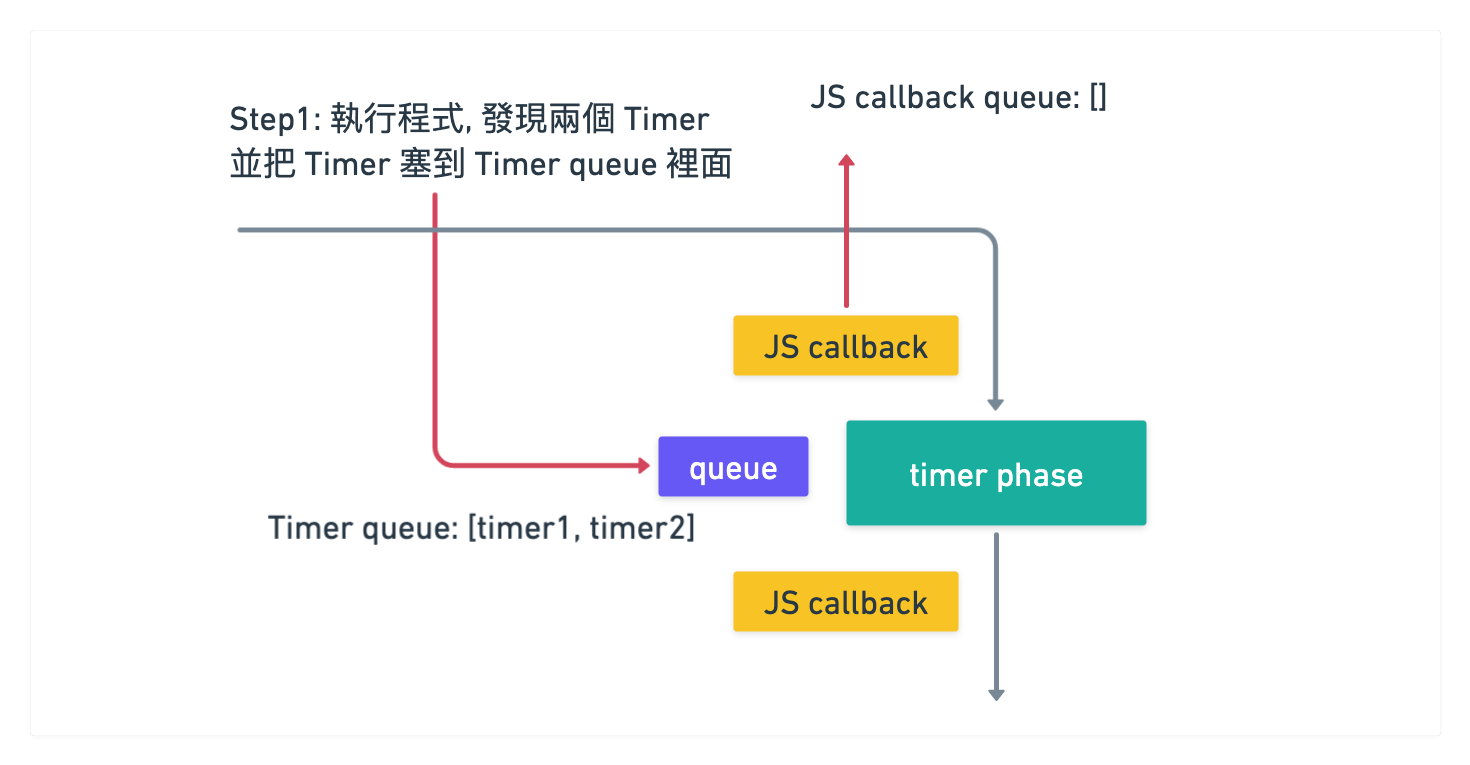
接著會到第一個 JS callback, 但因為裡面沒東西所以啥事都不做
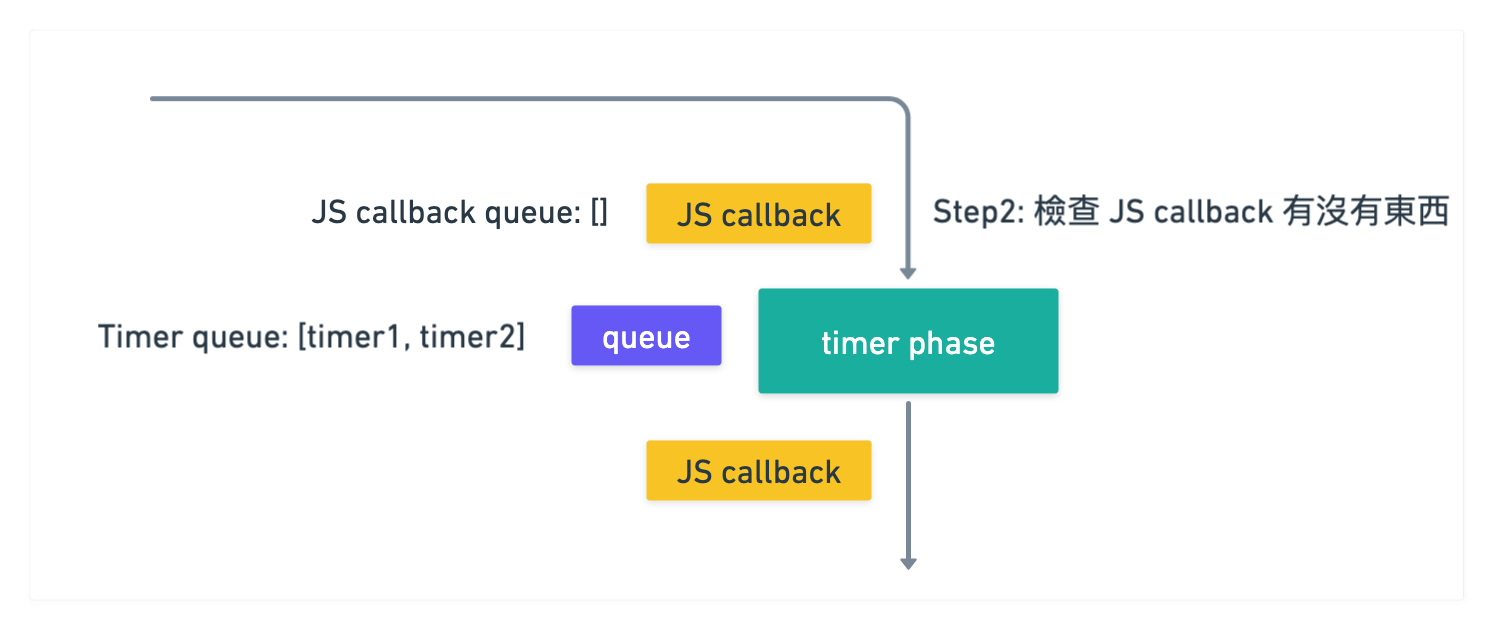
此時執行到 timer phase 的時候, 檢查發現有兩個 timer 可以執行
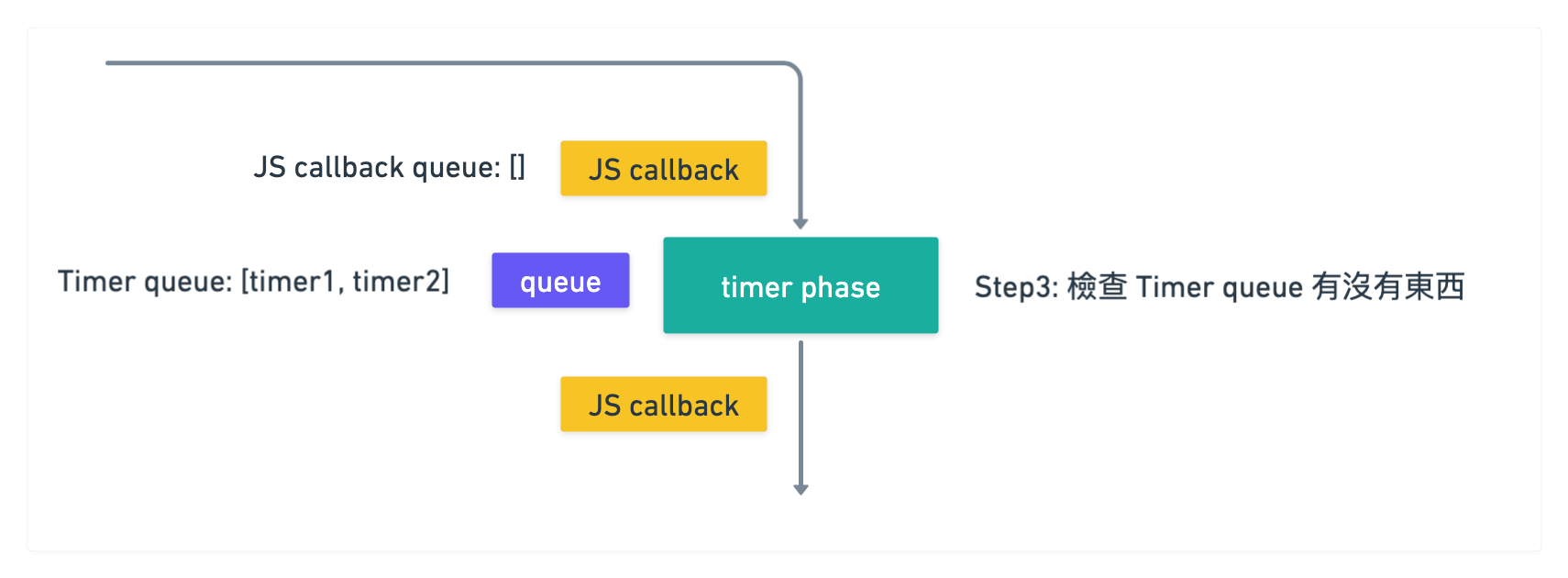
於是就先執行 dequeue 把 timer1 拿出來去執行 callback
執行後發現裡面有一個 promise 可以呼叫
於是把 promise callback 塞入到 JS callback queue 裡面
此時 JS callback queue 裡面就會有 [promise1 callback]
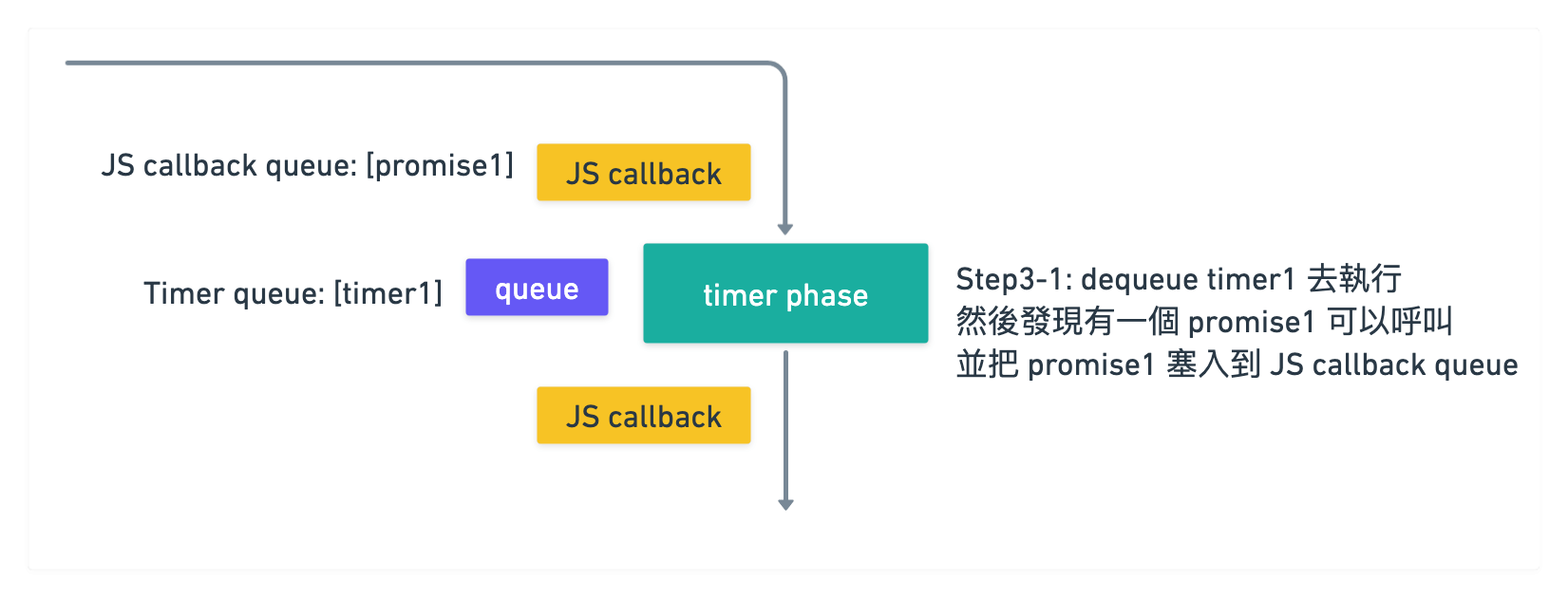
接著繼續 dequeue 把 timer2 拿出來執行 callback
接著一樣發現有一個 promise 可以呼叫
所以最後 JS callback queue 裡面變成 [promise1 callback, promise2 callback]
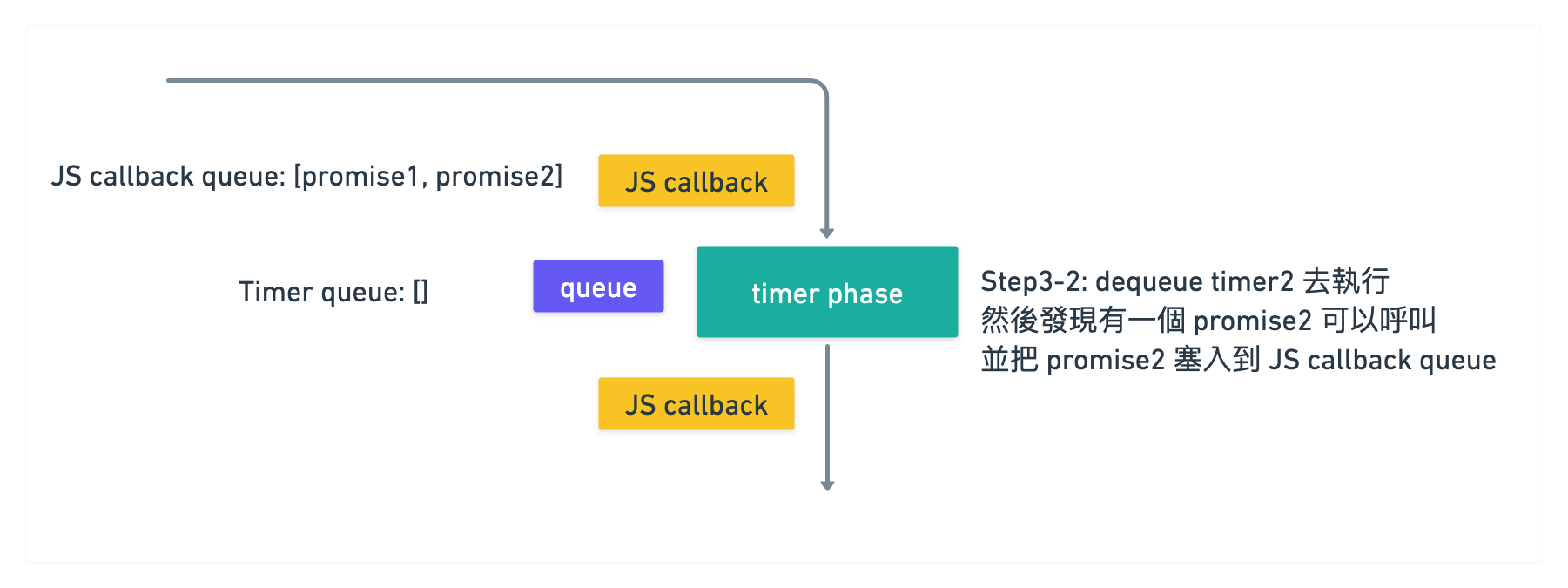
timer phase 結束後, 要進入到 pending callback phase 之前
會先去檢查 JS callback queue 裡面有沒有可以執行的 callback
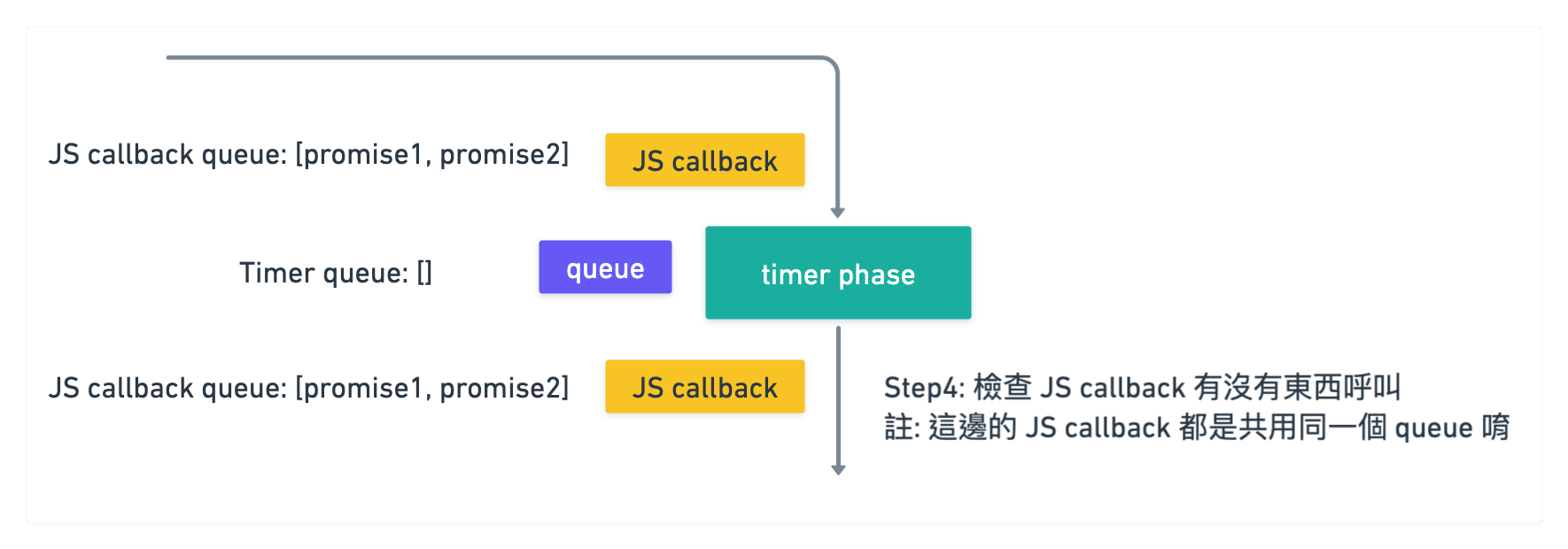
於是發現 [promise1 callback, promise2 callback] 在裡面
就按照 FIFO 的概念先執行 promise1 callback, 再來是 promise2 callback
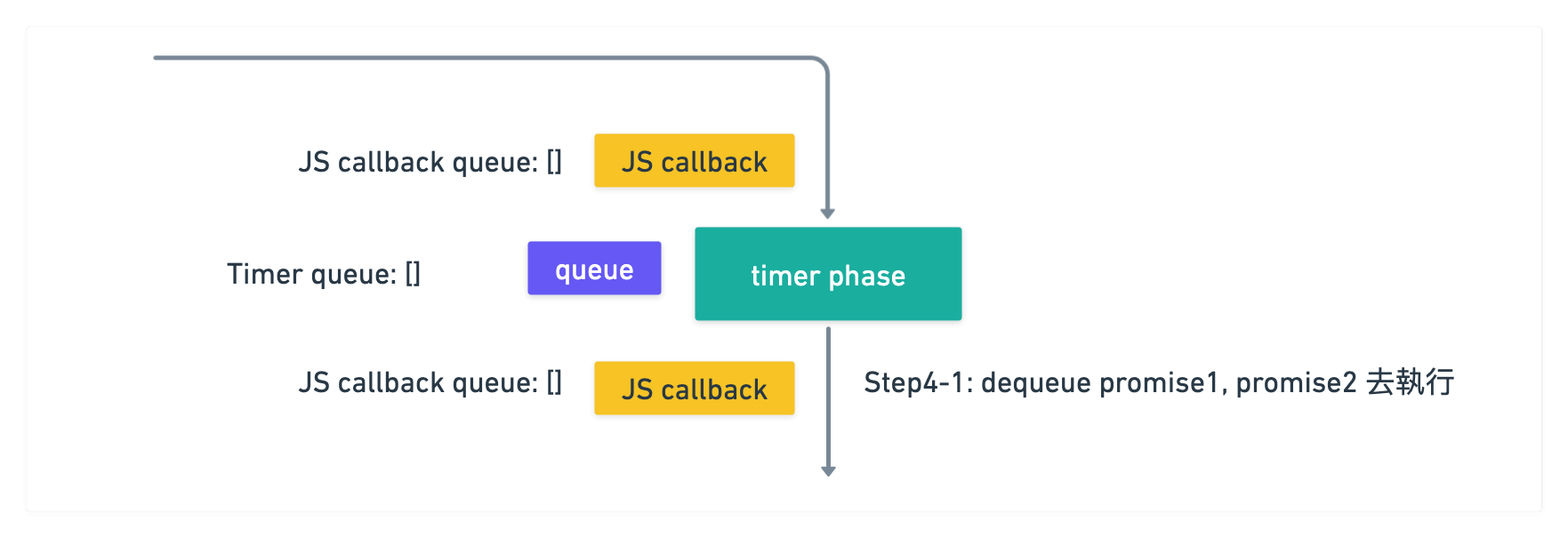
所以順序為 timer1 -> timer2 -> promise1 -> promise2
v11 以後思考方式
接著 v11 更改過後是會在每一次執行『每一個』 timer 之後, 直接去檢查 JS callback 裡面
有沒有可以執行的 callback, 有的話就直接去執行
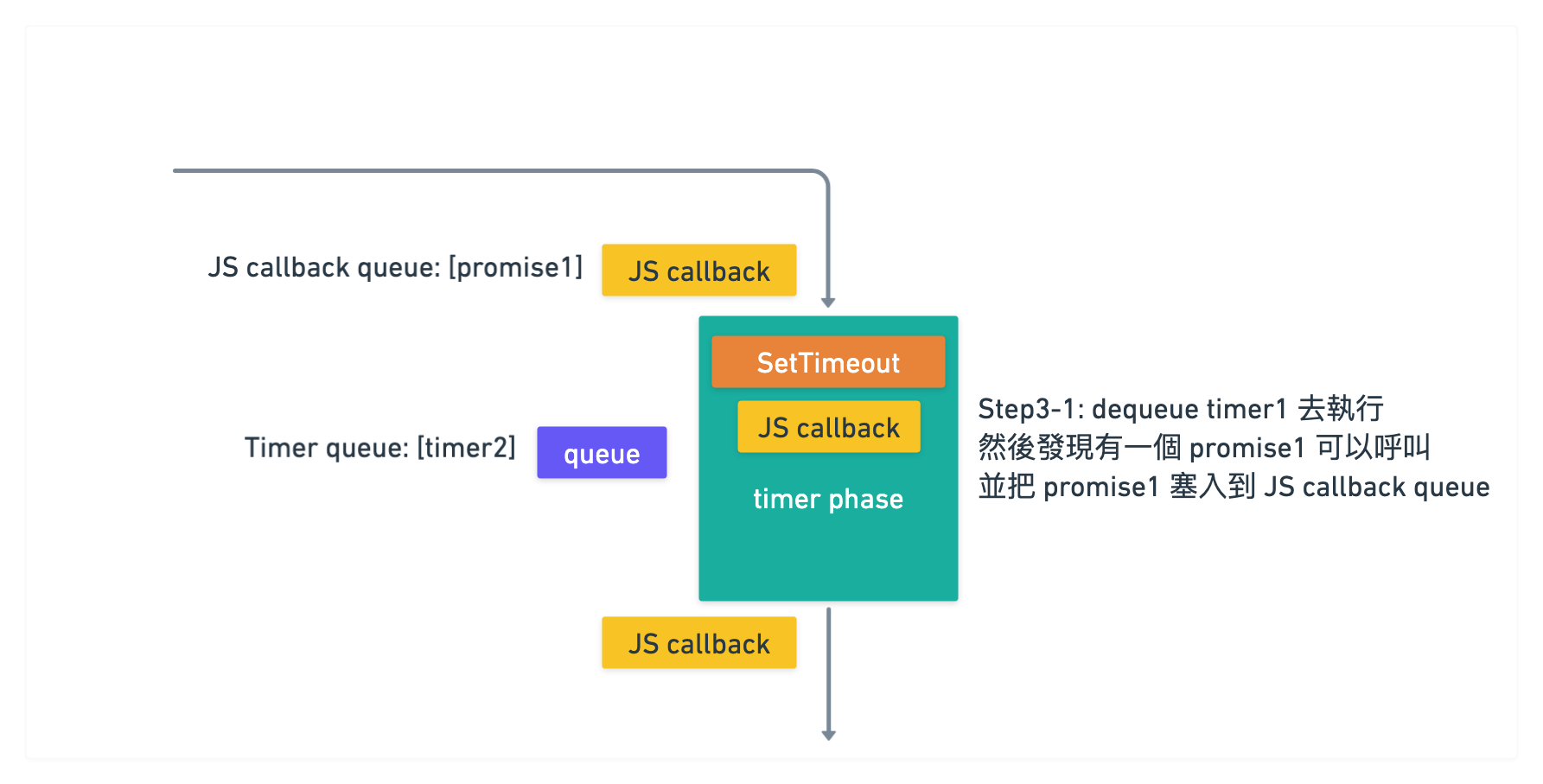
所以執行到 timer phase 的時候, 因為 queue 裡面有兩個 timer 可以執行
於是就先執行 dequeue 把 timer1 拿出來執行
執行後發現裡面有一個 promise 可以呼叫
於是把 promise1 callback 塞入到 JS callback queue 裡面
目前 JS callback queue 裡面有 [promise1 callback]
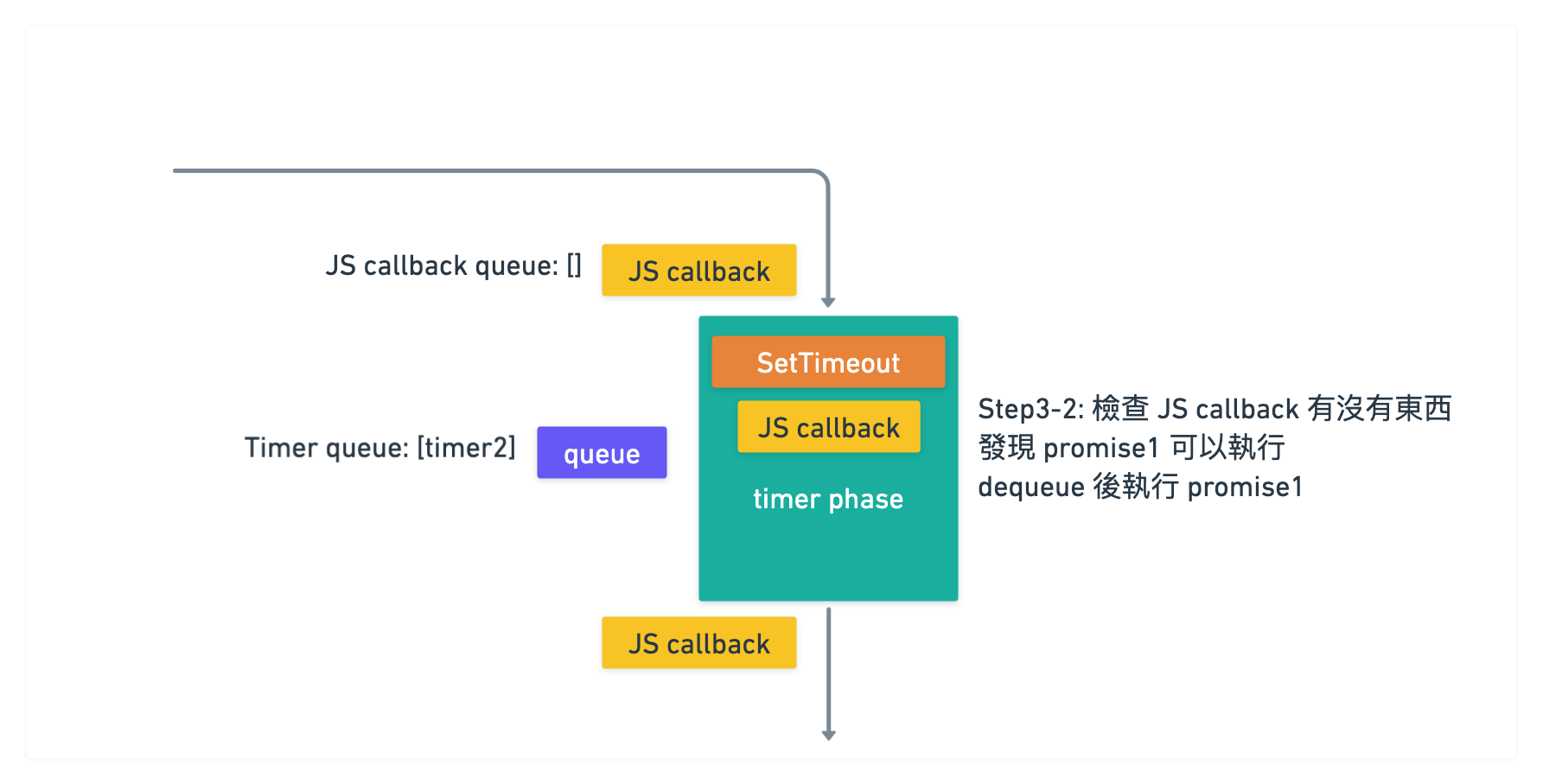
此時因為 timer1 執行完了, 接著會去檢查 JS callback queue 裡面有沒有東西
結果發現有一個 [promise1 callback] 在裡面是可以執行的
於是 dequeue promise1 後, 執行其 callback
那麼 JS callback queue 裡面就變空的 []
接著繼續 dequeue 把 timer2 拿出來執行完後
一樣發現 promise, 塞入到 JS callback queue 裡面
目前 JS callback queue 裡面有 [promise2 callback]
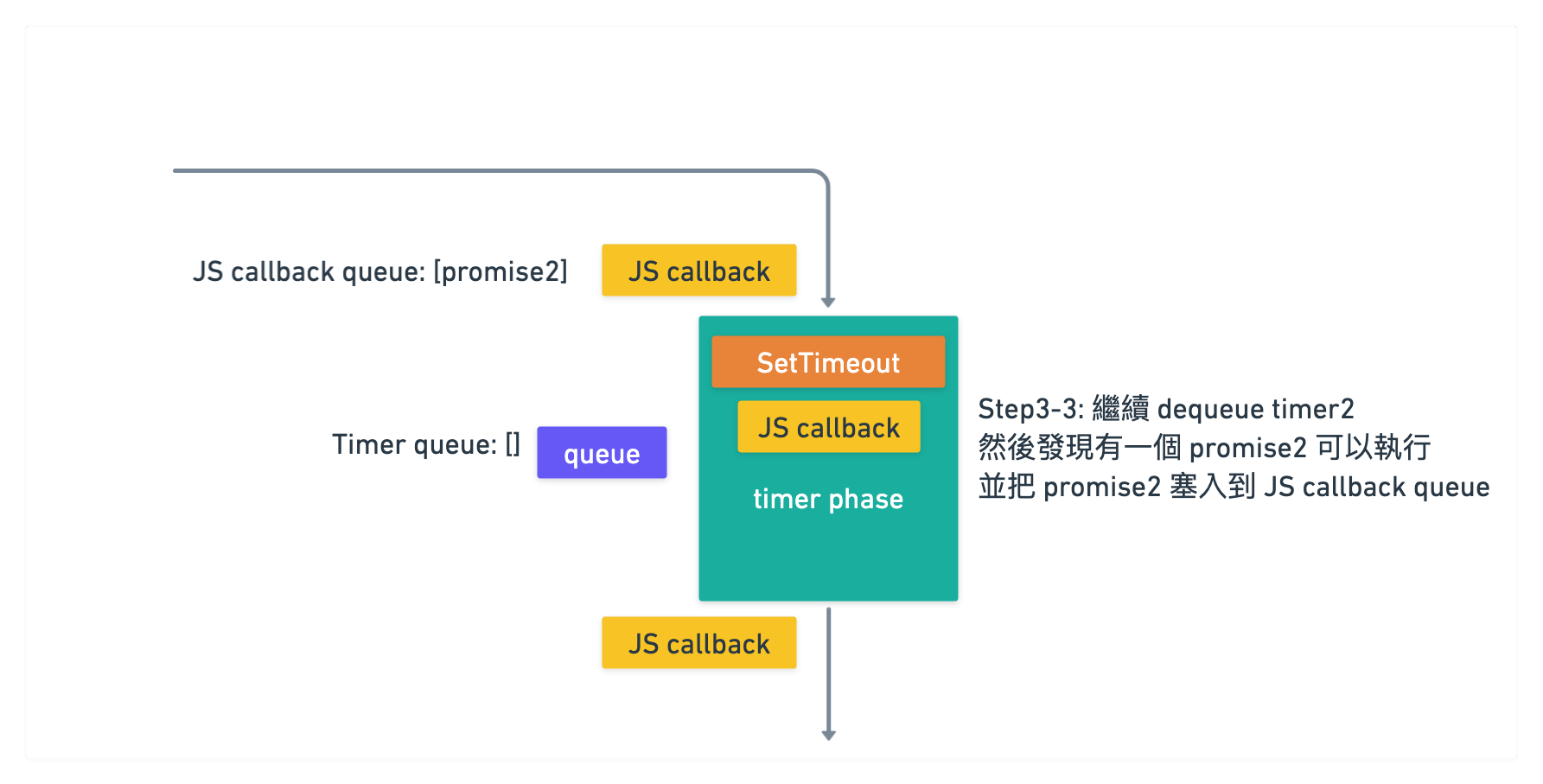
當 timer2 執行完後, 一樣檢查 JS callback queue
發現裡面有 [promise2 callback], dequeue promise2 後執行其 callnack
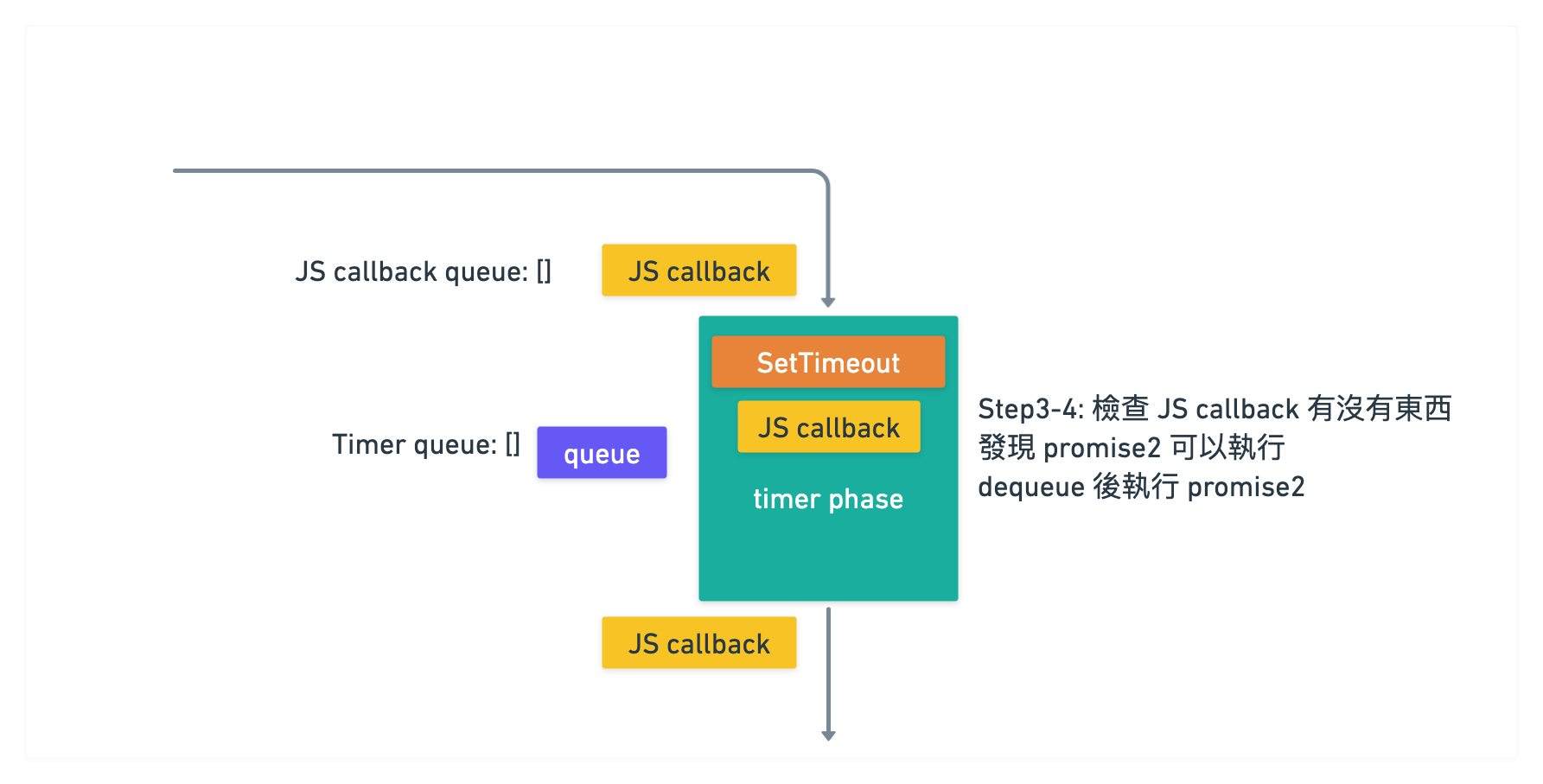
所以順序為 timer1 -> promise1 -> timer2 -> promise2
Node.js Event Loop 差異緣由?
那為什麼會有之前之後版本的差異呢?
其實源自於 Github Issue MacroTask and MicroTask execution order
這個 Issue 提出來之後, 就針對執行 microtask 的時間點去做調整符合瀏覽器的執行結果
這時才出現了 v11 版本的 Event Loop
介紹完 Event Loop 後, 常常會有一個隨著 Event Loop 一起被問的問題
『Node.js 是 Single Thread 嗎? 』
我覺得解釋不如直接跑程式範例讓你看看
Node.js 其實不是 Single Thread?
我寫了一個 setTimeout 的程式, 設定 6000 秒後會執行 callback
我們就來看看 Node 運行時的背景解析情況
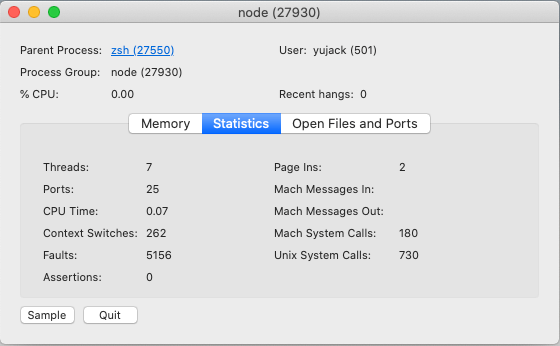
會發現 Node.js 實際上執行的 Thread 其實不止一個
這樣就不符合大家講 Node.js 是 Single Thread 的定義了?
其實大家講的 Single Thread 就是文章上半段筆者介紹的 Event Loop 的部分
而我們要怎麼證明 Event Loop 是 Single Thread 呢?
假設當你的程式中有出現 CPU 密集計算的程式時, 是會 block Event Loop Thread
進而導致各式各樣的 callback 無法執行, 可以來看一個最簡單的範例
先看看一般讀檔程式的執行順序
const fs = require("fs")
fs.readFile("./a.js", () => {
console.log("read file!")
})
console.log("test");
// test
// read file!
但萬一我在 console.log("test") 後面接一個無限的 while loop 呢?
我讀檔案的 callback 就這樣被鎖死, 永遠都不會執行到了
const fs = require("fs")
fs.readFile("./a.js", () => {
console.log("read file!")
})
console.log("test");
while(true) {}
// test
所以當談到 Single Thead 時
有些人會誤解 Node.js 就是 Single Thread 的一種語言
但實際上並不是, 真正 Single Thead 是 Event Loop 這整個機制
也就是執行 JavaScript 的 Thread 只有一條而已
雖然剛剛已經有一個例子證明執行 CPU 密集計算的程式時, 會 block Event Loop
但有沒有可能在執行 CPU 密集計算的程式時, 卻不會 block Event Loop?
答案是: 100% 可能
crypto
我們來看一個 Node.js 原生模組 crypto 執行的範例
這裏 crypto 是去做一個 hmac 的計算並去迭代 10 萬次一直跑計算
這是一個很耗費 CPU 計算的模組, 在我電腦上面跑大約耗費 500ms 左右,
const crypto = require("crypto");
const start = Date.now();
crypto.pbkdf2('a', 'b', 100000, 512, 'sha512', () => {
console.log('1:', Date.now() - start);
});
// 1: 5xx ms
然而當我在往上加一個的話會各是幾秒呢?
其實也是一樣各花 5xx ms
const crypto = require("crypto");
const start = Date.now();
crypto.pbkdf2('a', 'b', 100000, 512, 'sha512', () => {
console.log('1:', Date.now() - start);
});
crypto.pbkdf2('a', 'b', 100000, 512, 'sha512', () => {
console.log('2:', Date.now() - start);
});
console.log("done")
// done
// 1: 5xx ms
// 2: 5xx ms
那麼為什麼我透過這樣疊加, 卻不會看到第二個執行完成時間是 1000ms 後呢?
先把這問題放在心中, 我們再繼續往下看一個範例
process.env.UV_THREADPOOL_SIZE = 1;
const crypto = require("crypto");
const start = Date.now();
crypto.pbkdf2('a', 'b', 100000, 512, 'sha512', () => {
console.log('1:', Date.now() - start);
});
crypto.pbkdf2('a', 'b', 100000, 512, 'sha512', () => {
console.log('2:', Date.now() - start);
});
console.log("done")
// done
// 1: 5xx ms
// 2: 10xx ms
咦!? 多加了一個 process.env.UV_THREADPOOL_SIZE = 1
然後時間卻變成我們預想的 1+1 的概念? UV_THREADPOOL_SIZE 這又是什麼?
因為實際在 Node.js 裡面, 某些 library 是透過底層 libuv 去執行
libuv 是實現 Node.js 整個運行機制中的功臣之一
libuv 提供了 Node.js Event Loop, Thread Pool 等等重要功能
在 Node.js 運行時, libuv 會預設建立 Thread Pool
而這個 Thread Pool 會預設包含四個 Thread 去讓 Node.js 使用
所以 Thread 1, 2 會同時去執行 pbkdf2, 所以跑出來的秒數才是一樣的
而這裡執行的 pbkdf2 就是所謂非同步執行, 是交由 Thread 1, 2 去執行的
至於前面有一張圖, 為何顯示七條 Threads
可以參考此篇 SO why-node-js-spins-7-threads-per-process 的討論
所以當 Thread Pool 的大小只有一個的時候
一次只有一個 Thread 能幫你執行 pbkdf2, 自然而然時間就會疊加上去
所以反過來說, 如果 Thread Pool 固定 4 個
但執行的 function 變成 8 個時候, 前面四個會是 5xx ms, 後面四個會是 1000ms
const start = Date.now();
const crypto = require("crypto");
const fs = require("fs");
function doHash() {
crypto.pbkdf2('a', 'b', 100000, 512, 'sha512', () => {
console.log('Hash:', Date.now() - start);
});
}
doHash();
doHash();
doHash();
doHash();
doHash();
doHash();
doHash();
doHash();
// Hash: 595
// Hash: 609
// Hash: 613
// Hash: 615
// Hash: 1212
// Hash: 1227
// Hash: 1230
// Hash: 1244
不過其實這 function 也有同步版本, 是由 Event Loop 這條 Thread 本身去執行的
這裡就會發現原本的 done 是等到前面兩個跑完, 才會被執行
const crypto = require("crypto");
const start = Date.now();
crypto.pbkdf2Sync('a', 'b', 100000, 512, 'sha512');
console.log('1:', Date.now() - start);
crypto.pbkdf2Sync('a', 'b', 100000, 512, 'sha512');
console.log('2:', Date.now() - start);
console.log("done")
// 1: 5xxms
// 2: 10xxms
// done
所以在寫 Node.js 千萬不要用 xxxSync 版本的 function
這種只有在一些特殊狀況可能會用到
以 fs.readFileSync 來說, 啟動 https 的 node.js 程式
一定要有 private key 和 certificate 才有辦法啟動
這時用 fs.readFileSync 去讀這兩個檔案就很適合
但像寫 API 程式中, 就先萬不要用 readFileSync 去寫
所以透過以上例子, 可以很清楚知道 Node.js 絕對不是 Single Thread
真正 Single Thread 的是 Event Loop
接著可能會有人想問, 那關於 檔案讀寫 和 網路 相關的執行, 也都是透過 libuv 嗎?
先讓我們看看下面的例子, 你就知道了
fs + crypto
我們先來看看執行 node a.js 去讀取 a.js 需要的秒數會多久
// a.js
const start = Date.now();
const crypto = require("crypto");
const fs = require("fs");
fs.readFile("./a.js", "utf8", () => {
console.log('FS:', Date.now() - start);
})
// 3-5 ms
可以看到只有 3-5 ms 的時間
但當我在讀檔後面, 加上四個 pbkdf2
const start = Date.now();
const crypto = require("crypto");
const fs = require("fs");
function doHash() {
crypto.pbkdf2('a', 'b', 100000, 512, 'sha512', () => {
console.log('Hash:', Date.now() - start);
});
}
fs.readFile("./a.js", "utf8", () => {
console.log('FS:', Date.now() - start);
})
doHash(); // A
doHash(); // B
doHash(); // C
doHash(); // D
// Hash: 540
// Hash: 548
// Hash: 549
// FS: 549
// Hash: 554
結果秒數變得跟 doHash 一樣長的時間了!?!?!?
?為什麼加上 doHash 後會影響 fs 的時間 !?
原因是因為 fs 是跟 pbkdf2 用同樣的 Thread Pool
還記得我們只有 4 個 Thread 嗎?
在程式一開始執行時, 這四條 Thread 是這樣分配的
fs -> Thread1
doHash // A -> Thread2
doHash // B -> Thread3
doHash // C -> Thread4
但當 Thread1 在執行 fs 的時候, 他只是把任務指派下去交給 File System 去做
實際上讀檔行為並不在 Thread1 發生
要等到 File System 真正讀完資料後, 是需要一段時間 (雖然這裡只需要 3-5 ms)
File System 讀完資料之後, 會再通知 Node.js 的 Thread
此時 Thread 就可以把 callback 丟到 Event Loop 去被執行
而這段時間就是在等 callback, 所以在等的這段時間, Thread1 會先不理
因為 Thread1 指派任務這件事情結束了
它也不知道什麼時候才能把 callback 丟到 Event Loop 去被執行
所以 Thread1 就會先去接著做 doHash // D 的事情
這時這四條 Thrad 分配變這樣
doHash // A -> Thread2
doHash // B -> Thread3
doHash // C -> Thread4
doHash // D -> Thread1
然後 doHash 需要花費大概 5xx ms 才能結束
但如果四條 Thread 都被佔著, 就算 File System 讀在快都沒用
因為他沒辦法通知其中一個 Thread
所以要等到 Thread 被釋放出去, 才能去迎接 fs 結束的事件通知
得到 fs 結束的事件通知後, Thread 才有辦法把 callback 丟到 Event Loop 去等待被執行
所以最後 fs 的時間, 才會變成 5xx ms, 遠比一開始的 1-5 ms 還要多很多
所以依照上面 case 這樣修改成以下的
把讀檔放在坐後面, 前面只留下 3 個 doHash, 這樣讀檔時間就又會變回來了
const start = Date.now();
const crypto = require("crypto");
const fs = require("fs");
function doHash() {
crypto.pbkdf2('a', 'b', 100000, 512, 'sha512', () => {
console.log('Hash:', Date.now() - start);
});
}
doHash(); // A
doHash(); // B
doHash(); // C
fs.readFile("./a.js", "utf8", () => {
console.log('FS:', Date.now() - start);
})
// FS: 8
// Hash: 547
// Hash: 548
// Hash: 549
原因就是 default Thread Pool 數量是四個
這邊剛好四個非同步的 function 要執行, 所以全部 Thread 都有事情做, 就不會發生剛剛的情況
所以可以繼續往下推. 如果再 fs 前面加一個 doHash 就又會變回去了
const start = Date.now();
const crypto = require("crypto");
const fs = require("fs");
function doHash() {
crypto.pbkdf2('a', 'b', 100000, 512, 'sha512', () => {
console.log('Hash:', Date.now() - start);
});
}
doHash(); // A
doHash(); // B
doHash(); // C
doHash(); // D
fs.readFile("./a.js", "utf8", () => {
console.log('FS:', Date.now() - start);
})
// Hash: 630
// FS: 637
// Hash: 659
// Hash: 659
// Hash: 668
所以回歸到問題『關於 檔案讀寫 和 網路 相關的執行, 也都是透過 libuv 嗎?』
從上面例子可以看到 fs 其實也是使用 libuv 的 Thread Pool 去執行的
那 Network 呢? 我們繼續看下一個例子
network + crypto
先看原本執行的時間
const http = require("http")
const start = Date.now();
function doRequest() {
http.request("http://localhost:4000", res => {
res.on("data", () => {
})
res.on("end", () => {
console.log("Request:", Date.now() - start);
});
}).end();
}
doRequest();
// Request: 30xx
那因為我設定我 localhost:4000 三秒後回傳
所以會發現大約在 3000ms 左右, 這時我把 pbkdf2 加上去看會變怎樣
const http = require("http")
const crypto = require("crypto")
const start = Date.now();
function doHash() {
crypto.pbkdf2('a', 'b', 100000, 512, 'sha512', () => {
console.log('Hash:', Date.now() - start);
});
}
function doRequest() {
http.request("http://localhost:4000", res => {
res.on("data", () => {
})
res.on("end", () => {
console.log("Request:", Date.now() - start);
});
}).end();
}
doRequest();
doHash();
doHash();
doHash();
doHash();
// Hash: 758
// Hash: 761
// Hash: 762
// Hash: 762
// Request: 3032
竟然還是 3000ms 以內 !?!?!? (Node.js 你也太怪了吧
所以這樣看起來的意思是 Network 相關的, 不會用 libuv 底層的 ThreadPool 去執行?
且慢, 我們把 doRequest 移動到最後面看看
const http = require("http")
const crypto = require("crypto")
const start = Date.now();
function doHash() {
crypto.pbkdf2('a', 'b', 100000, 512, 'sha512', () => {
console.log('Hash:', Date.now() - start);
});
}
function doRequest() {
http.request("http://localhost:4000", res => {
res.on("data", () => {
})
res.on("end", () => {
console.log("Request:", Date.now() - start);
});
}).end();
}
doHash(); // A
doHash(); // B
doHash(); // C
doHash(); // D
doRequest();
// Hash: 609
// Hash: 613
// Hash: 621
// Hash: 624
// Request: 3620
竟然變成 36xx ms ... !?!?
這裡的時間差卻又跟 fs 一樣會被 doHash 影響!?
但讓我們再看一個連續一次性呼叫多個 http request case
const http = require("http")
const start = Date.now();
function doRequest() {
http.request("http://localhost:4000", res => {
res.on("data", () => {
})
res.on("end", () => {
console.log("Request:", Date.now() - start);
});
}).end();
}
doRequest();
doRequest();
doRequest();
doRequest();
doRequest();
doRequest();
doRequest();
doRequest();
// Request: 3025
// Request: 3035
// Request: 3036
// Request: 3036
// Request: 3036
// Request: 3037
// Request: 3037
// Request: 3037
會發現都是 3000ms ... 秒數其實都是相當接近的, 這究竟是什麼回事 !?
這跟行為跟剛剛 fs 連續呼叫 8 個不太一樣
我們先整理目前遇到的三個 network case
- doRequest 後, 連續四個 doHash -> 3000ms
- 連續四個 doHash 後, doRequest -> 3600ms
- 執行連續好幾個 doRequest -> 3000ms
先針對 case 2 說明
原因是發 Request 這件事情, 還是要交由 Thread Pool 去觸發
所以必須要等到空閒的 Thread 才能去執行 doRequest
那為什麼 case 1 先執行 doRequest 不會造成其中一個 doHash +3000ms 呢?
原因是實際執行發請求的地方, 並不是在 Thread 本身發生
Thread 只是把這個任務指派出去, 並指派到 OS, 交由 OS 真正去執行發請求
所以並不是 Thread 本身去執行發請求的任務, 這點跟執行 fs 是一樣的
這也是為什麼 case 3 連續執行好幾個 doRequest
不會像前面好幾個 doHash 一樣會互相影響
在 doRequest 中 Thread 只是指派任務, Thread 本身並不會執行
在 doHash 中 Thread 是實際執行任務
所以兩者運行起來才會有差別, 不過凡事都有個『但書』
再讓我們來看 case 4, 更改的地方是我從 localhost 改成 127.0.0.1
const http = require("http");
const crypto = require("crypto");
const start = Date.now();
function doHash() {
crypto.pbkdf2("a", "b", 100000, 512, "sha512", () => {
console.log("Hash:", Date.now() - start);
});
}
function doRequest() {
http.request("http://127.0.0.1:4000/test", res => {
res.on("data", () => {
});
res.on("end", () => {
console.log("Request:", Date.now() - start);
});
}).end();
}
doHash();
doHash();
doHash();
doHash();
doRequest();
// Hash: 697
// Hash: 700
// Hash: 700
// Hash: 703
// Request: 3014
按照前面 case2 的想法, 他應該會是 3600ms 對吧?
但實際執行後, 其實只有 3000ms ...
謎之聲: 乾 Node.js 你也太怪了吧, 不是說好給 Thread Pool 去指派任務嗎 !?!?! (翻桌
原因是當 http 模組發請求是用『IP』而不是『hostname』的時候
此時去指派任務的人, 就不是 Thread Pool, 而是 Event Loop 本身這條 Thread
但為何會有這樣的區別, 原因是 http 底層用了 dns.lookup 去解析 hostname
而 dns.lookup 實作方式就是用 Thread Pool
所以才會有下面這張圖的解釋, 讓大家了解 node 各模組所屬的組別是什麼

以上介紹完 Event Loop Node.js 版本
接著我們最後來用文章最一開始的例子, 來去比對瀏覽器和 Node.js 版本中執行的差異吧!
瀏覽器和 Node.js 執行邏輯差異
我們一樣拿最一開始的程式碼來解釋, 那因為 Node.js 解釋過了
所以這邊用瀏覽器邏輯去解釋, 不過會多加 function name, 會方便等等截圖
setTimeout(function timer1 () {
console.log('timer1')
Promise.resolve().then(function promise1() {
console.log('promise1')
})
}, 0)
setTimeout(function timer2 () {
console.log('timer2')
Promise.resolve().then(function promise2() {
console.log('promise2')
})
}, 0)
瀏覽器中存在 task 和 microtask 的概念
每一次的 setTimeout 的 callback 裡面都是被歸類在 task 的範疇
所以上面執來說, 總共開了兩輪的 task 讓瀏覽器執行
第一輪 task 會印出 timer1
然後發現有一個 microtask 可以執行 (promis1), 於是就執行印出 promise1
那因為第一輪 task 已經沒有 microtask 可以執行, 於是結束第一輪 task
第二輪 task 會印出 timer2
然後發現有一個 microtask 可以執行 (promis2), 於是就執行印出 promise2
那因為第一輪 task 已經沒有 microtask 可以執行, 於是結束第二輪 task
從瀏覽器的開發者工具中的 performance 去檢測也會得到一樣的結果
前面的 task 包含 timer1 + promise1
後面的 task 包含 timer2 + promise2

雖然在瀏覽器和 Node.js 兩者執行結果一樣, 但概念是不一樣的
以瀏覽器來說, 執行 Event Loop 兩輪才把程式跑完
以 Node.js 來說, 都還沒進到 Event Loop 一半, 程式碼就都已經跑完了等著要跳出 Event Loop
還蠻有趣的對吧 XD
補充 - v10 執行結果有時跟 v11 一樣
還記得一開始有提到 v8, v10 執行文章一開始範例的結果
有時候會跟 v11 一樣嘛? 看完 Event Loop 後我們來解析這個情況
我們先從『符合邏輯』的方式下去猜想為何有時候會一樣
在執行整個程式之後, 把 timer1, timer2 放到 timer phase queue 之後
準備要去觸發 timer1, timer2 callback
因為是 timer, 所以他執行的條件就是『你設定的時間已經過期』
這個 timer callback 才會被觸發
所以有可能是因為 timer1 已經到達『過期的時間』
但 timer2 卻還沒到達『過期的時間』
才導致這樣順序 timer1 -> promise2 -> timer2 -> promise2?
更詳細的說明的話
第一輪 Event Loop 到了 timer phase 之後
發現了只有 timer1 過期可以執行, 於是只執行 timer1 的 callback
但此時 timer2 還沒到可以執行的階段, 於是就先跳過
準備進到 pending task phase 之前
因為有一個 JS Callback, 這時就先把 promise1 給印出來
接著到了 poll 階段時, 因為 poll phase queue 為空
但因為有設置 timer, 且已經到達過期時間
於是 Event Loop 就繞回去 timer 階段
此時 timer 階段有一個 timer2
就按照 timer phase 執行 timer2 callback
然後進入到 pending task 之前的 JS callback
又執行了 promise2
這才導致了順序不一樣的問題
但 ... 兩個 timer 都設置為 0, 這種可能性是會發生的嗎?
我們先來看看 node.js 針對 setTimeout 使用的說明
When delay is larger than 2147483647 or less than 1, the delay will be set to 1.
Non-integer delays are truncated to an integer.
有沒有發現一個神奇的點, 也就是說 0 根本不存在
你設置 0 的話, 他會直接把你的 0 改成 1
所以實際上程式運行是長這樣
setTimeout(()=>{
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 1)
setTimeout(()=>{
console.log('timer2')
Promise.resolve().then(function() {
console.log('promise2')
})
}, 1)
而這裡的 1ms 都是所謂相對時間
也就是程式執行當下的相對時間
這樣的時間差 + 機器執行的效能花式組合後(?
就會達成以下狀況發生, 這時可以再回去看看我們猜想的流程其實是正確的
- timer1 就可能先過期且可以執行
- timer2 就還沒過期, 所以還不能執行
所以其實 v11 版本也是非常有可能造成以上時間差的問題
但因為 v11 機制整體改掉的關係, 所以不會偶爾有執行順序的差別
後記
這次 Event Loop - Node.js 篇就介紹到這邊了
如果內容有誤或是不清楚的, 非常歡迎大家來找我討論!
之後如果有想到什麼其他更好例子, 可能會再慢慢補上來, 讓整體概念更加清楚
因為這篇是以概念為主去針對 Event Loop 介紹
下一篇的話, 就會稍微硬一點, 可能會實際來看看 libuv 源碼是怎麼寫 XD
另外若文章有描述不對或怪怪的地方, 請各位大大不要手軟直接指認 XD
References



![[第九週] 資料庫系統簡介](/@peichang6/0555f073ad354ee5a77241c494bb7d85?utm_source=coderbridge-com&utm_medium=indie_related_post_img&utm_campaign=Event Loop 運行機制解析 - Node.js 篇_[第九週] 資料庫系統簡介_@peichang6_https://static.coderbridge.com/images/covers/default-post-cover-2.jpg)


