一般情形下list裡的數字是沒有照順序排列的,此時我們如果想得知兩個list裡到底重複了幾個數字(也許可以推廣到抄襲辨識的比對),方法1程式碼大致如下:
def overlap(s,t):
"""Return the overlap between S and T."""
>> overlap([3, 5, 4, 6, 9, 7, 10],[7, 3, 5, 1, 8])
>> 3
count = 0
for i in s:
for j in t:
if i == j:
count+=1
return count
但此時產生一個問題:時間複雜度過高,我們反覆將兩個list內的value比對,如果今天單一個list的length就有n這麽大,我們估計就需要花費 n^2 的時間跑完我們的程式。
但如果今天在特殊情形,我們拿到兩組皆已排序的數列,或是我們利用Python內建的sorted()函數幫助我們由小至大排序兩組list,我們就可以將程式碼修改成方法2:
def fast_overlap(s, t):
"""Return the overlap between sorted S and sorted T.
>> fast_overlap([3, 4, 5, 6, 7, 9, 10],[1, 3, 5, 7, 8])
>>3
"""
i, j,count = 0,0,0
while i < len(s) and j < len(t):
if s[i]==t[j]:
count, i, j = count+1, i+1, j+1
elif s[i] < t[j]:
i += 1
else:
j += 1
return count
原理如下:
首先將兩組list都整理成sorted
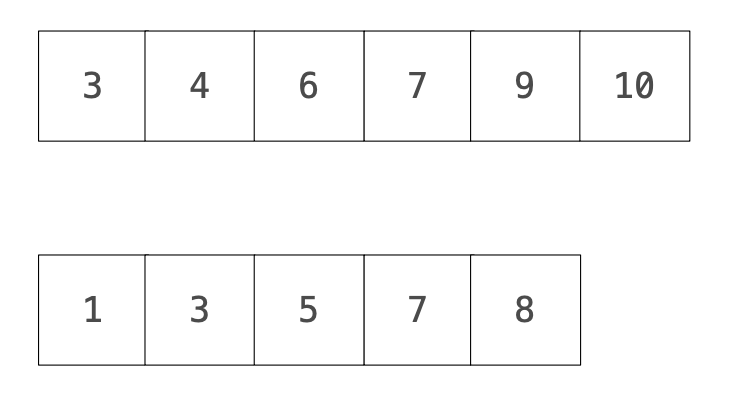
先從起始位置,也就是s[0]及t[0]開始比較
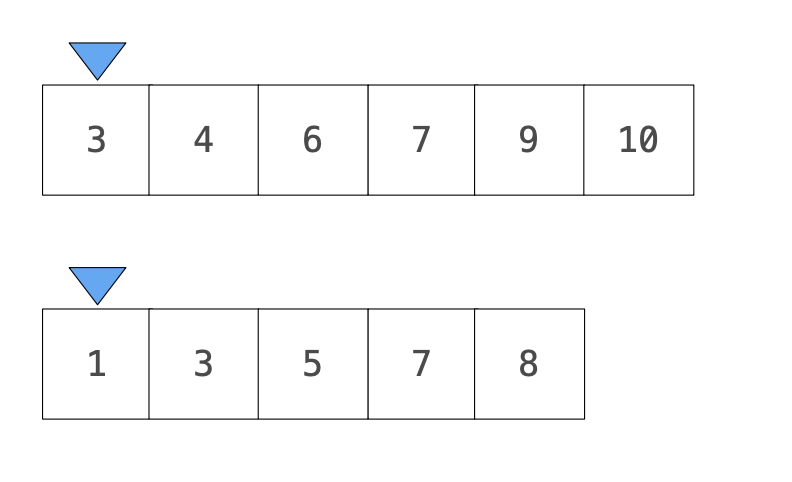
比較小的數列就直接往前推進
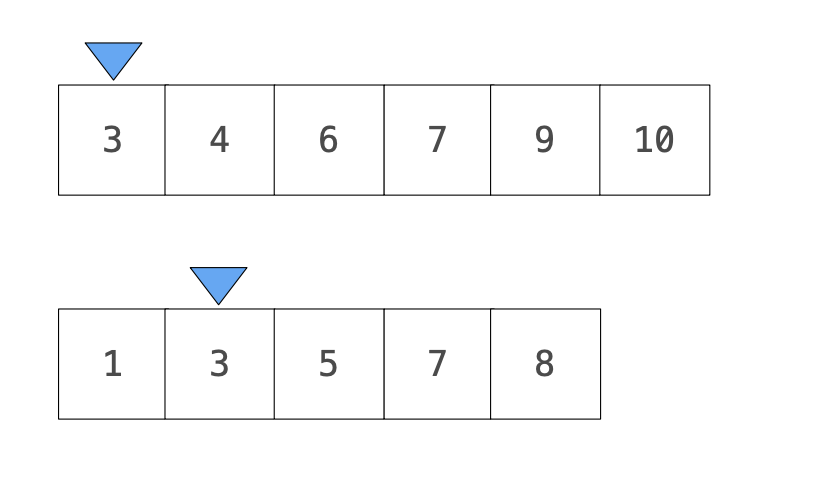
當遇到數字相同時,計數器加1,並且兩數列同時前進
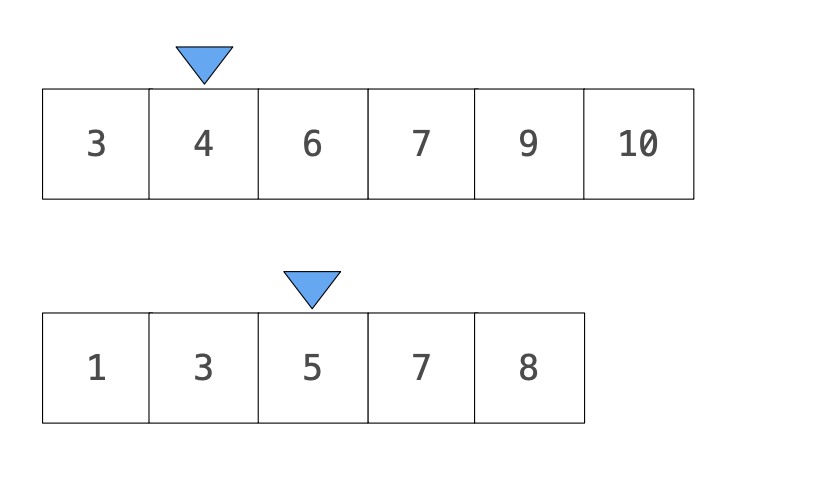
以此類推run完,不斷前進的方式就是直接不去看已經跑過的值,因為前面比較小的值也必定不會跟另一個數列後段較大的值重複了,因此時間複雜度大致推算為 n。
參考資料:UC Berkeley CS61A



![[ week 1 ] 前端、後端的差異?](https://alirong.coderbridge.io/2020/06/19/week1-front-end-vs-back-end/?utm_source=coderbridge-com&utm_medium=indie_related_post_img&utm_campaign=Python -「快速」算出兩排序數列中重複的次數_[ week 1 ] 前端、後端的差異?_@vick12052002_https://static.coderbridge.com/images/covers/default-post-cover-2.jpg)


