<續前>
現在思考一下,極限值 $p\to 0$ 和 $N\to\infty$, 但是 $pN = \nu$ 的值卻維持不變。
在這個例子,v 是"成功"的期望值,或是在一大量資料集合中的任一事件出現相對低的頻率。 v 是單一參數, 稱為帕松分布(Poisson distribution)平均值,這個分布描述許多現象,包括許多社群資料的變數。
- 來自消防局的一小時間的tweet數量 $\longrightarrow $ 大量的 N
- 使用者位置 = "Boulder, Colorado, United States"的機率 $\longrightarrow$ 少量的 $p$
所以,平均值 v 的帕松分布(Poisson distribution) 將用於描述,在一個大樣本中,使用者位置 = "Boulder, Colorado, United States"的tweet的數量
帕松分布的函數為 :
$P(k;\nu) = \frac{\nu^k e^{-\nu}}{k!}$
讓我們來檢視分布的形狀 :
nu = 3 # Poisson mean...the most likely value
n = nu*3 # this simply sets a range; it is not a parameter of the distribution
k = scipy.linspace(0,n,n+1) # create bins
pmf = scipy.stats.poisson.pmf(k,nu)
plt.bar(k,pmf)
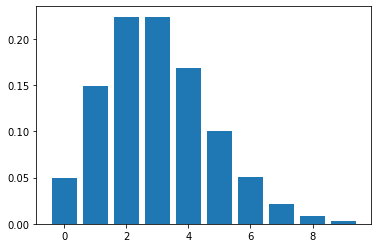
注意事項 :
- 這個分布是一個離散變數函數
- 這個分布有一個連續參數(continuous parameter)
- 對於少量 v 這個分布是不對稱的
- 對於大量 v 這個分布有變成對稱
結論 : 帕松分布(Poisson distribution) 可以被期望用來展示在一大量試驗中觀察到稀有事件的次數
假設檢定(Hypothesis Tests) 和 p-值(p-values)
科學方法的題外話
科學方法並沒有證明一個假設是正確的(true/correct)。相反的,假設被和假設不一致的實驗結果推翻。
在許多科學領域,一致或不一致是離散狀態。在統計參與的系統下,事情更複雜。我們必須定義甚麼程度下的不一致被視爲推翻假設。
假設類型
要量化測試一個假設,我們需要量化的假設和一些資料。
假設範例 :
- 使用者位置 = "Boulder, Colorado, United States"的 tweets 的比率是帕松分布(Poisson distribution),且平均值是 4.5/小時
- 使用者位置 = "Boulder, Colorado, United States"的 tweets 的比率是帕松分布(Poisson distribution),且平均值是 4.5/10k tweets
- 在過去1小時 提到 @ 多於1000次的 Twitter 使用者人數是常態分佈且平均值是 301,變異數是 200。

 part 2_React 入門 6 - Hooks: useEffect_@urlun0404_https://static.coderbridge.com/images/covers/default-post-cover-1.jpg)

![[Golang] slice 作為參數傳入 func 的注意事項](https://kitecloud-backend.coderbridge.io/2020/08/15/golang-slice-作為參數傳遞時的注意事項/?utm_source=coderbridge-com&utm_medium=indie_related_post_img&utm_campaign=Day02 典型統計應用在社群媒體分析(Classical statistics applied to social data) part 2_[Golang] slice 作為參數傳入 func 的注意事項_@kitecloud213_https://static.coderbridge.com/images/covers/default-post-cover-2.jpg)

 part 2_4. 傅立葉轉換_@tzupingkao_https://static.coderbridge.com/images/covers/default-post-cover-3.jpg)
